About STL을 보시는 분은 대부분 아직 STL을 잘 모르는 분들이라고 생각합니다. 제가 일하고 있는 게임업계는 주력 언어가 C++입니다. 그래서 취업 사이트에 올라온 프로그래머 채용 공고를 보면 필수 조건에 거의 대부분이 C++와 STL 사용 가능이 들어가 있습니다. 게임 업계뿐 아니라 C++을 사용하여 프로그래밍하는 곳이라면 대부분 C++과 STL을 사용하여 프로그램을 만들 수 있는 실력을 필요로 합니다.
C++ 언어를 배우고 사용하는 프로그래머라면 STL을 배우면 좋고, 특히 게임 프로그래머가 되실 분들은 STL을 꼭 사용할 줄 알아야 됩니다.
작년 여름부터 About STL을 쓰기 시작하여 지금은 2009년이 되었습니다. About STL 집필 계획으로는 이제 반 정도 도달한 것 같습니다. 앞으로 남은 반도 STL을 습득하는데 도움이 되도록 저도 최대한 노력할 테니 2009년에는 STL을 꼭 마스터하기를 바랍니다.
6.1 시퀸스 컨테이너와 연관 컨테이너
이전 회까지는 STL의 컨테이너에 대해서 설명했었습니다. STL 컨테이너는 크게 시퀸스 컨테이너와 연관 컨테이너로 나눕니다.
시퀸스 컨테이너는 vector, list, deque와 같이 순서 있게 자료를 보관합니다.
연관 컨테이너는 어떠한 Key와 짝을 이루어 자료를 보관합니다. 그래서 자료를 넣고, 빼고, 찾을 때는 Key가 필요합니다.
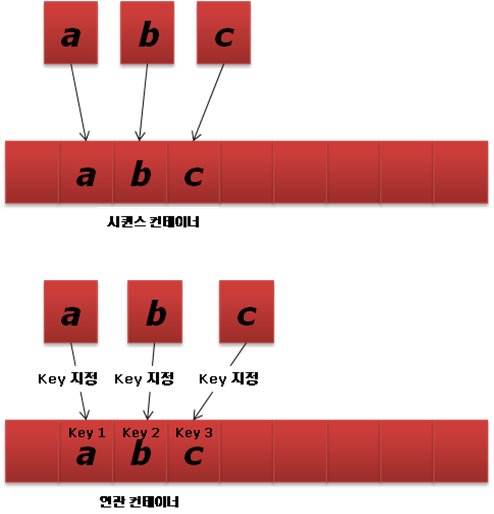
[그림 1] 시퀸스 컨테이너와 연관 컨테이너
시퀸스 컨테이너는 많지 않은 자료를 보관하고 검색 속도가 중요한 경우에 사용하고, 연관 컨테이너는 대량의 자료를 보관하고 검색을 빠르게 하고 싶을 때 사용합니다. 제가 만드는 온라인 게임 서버에서는 보통 접속한 유저들의 정보를 보관할 때 가장 많이 사용합니다.
6.2 연관 컨테이너로는 무엇이 있을까요?
연관 컨테이너로 map, set, hash_map, hash_set이 있습니다. 이것들은 Key로 사용하는 값이 중복되지 않은 때 사용합니다. 만약 중복되는 key를 사용할 때는 컨테이너의 앞에 'multi'를 붙인 multi_map, multi_set, hash_multimap, hash_multiset을 사용합니다. Key의 중복 허용 여부만 다를 뿐 사용방법은 같습니다.
6.2.1 map, set 과 hash_map, hash_set의 차이는?
가장 쉽게 알 수 있는 큰 차이는 이름 앞에 'hash'라는 단어가 있냐 없냐의 차이겠죠.^^
네, 'hash'라는 단어가 정말 큰 차이입니다.
map과 set 컨테이너는 자료를 정렬하여 저장합니다. 그래서 반복자로 저장된 데이터를 순회할 때 넣은 순서로 순회하지 않고 정렬된 순서대로 순회합니다. hash_map, hash_set은 정렬 하지 않으며 자료를 저장합니다. 또 hash라는 자료구조를 사용함으로 검색 속도가 map, set에 비해 빠릅니다.
map, set과 hash_map, hash_set 중 어느 것을 사용할지 생각할 때는
map, set의 사용하는 경우 : 정렬된 상태로 자료 저장을 하고 싶을 때.
hash_map, hash_set : 정렬이 필요 없으며 빠른 검색을 원할 때.
를 가장 큰 조건으로 보면 좋습니다.
6.2.2 hash_map, hash_set은 표준은 아닙니다.
위에 열거한 연관 컨테이너 중 map과 set은 STL 표준 컨테이너지만 hash_map, hash_set은 표준이 아닙니다. 그래서 보통 STL 관련 책을 보시면 hash_map과 hash_set에 대한 설명은 없습니다. hash_map, hash_set을 쓰려면 라이브러리를 설치해야 할까요? 그럴 필요는 없습니다. STL 표준은 아니지만 오래되지 않은 C++ 컴파일러에서는 대부분 지원합니다. 윈도우에서는 Visual Studio.NET의 모든 버전에서 지원합니다.
STL 표준도 아닌 hash_map을 설명하려는 이유는 대부분 C++ 컴파일러에서 지원하고, 새로운 C++ 표준에서는 정식으로 STL에 들어갈 예정이며 현업에서 프로그래밍할 때 아주 유용하게 사용하는 컨테이너이기 때문입니다.
[참고]
2010년 이내에 새로운 C++ 표준이 만들어질 예정인데 표준이 공표되기 전에 TR1으로 일부 공개하고 있습니다. TR1에서는 hash_map, hash_set과 거의 같은 컨테이너인 unordered_map, unordered_set이 준비되어 있습니다. hash_map, hash_set과 이름만 다를 뿐 컨테이너의 자료구조나 사용방법이 거의 같습니다.
그래서 hash_map, hash_set 사용법을 익히며 자동으로 unordered_map, unordered_set도 익히게 됩니다.
6.3 hash_map의 자료구조
hash_map의 자료구조는 '해시 테이블'입니다.
아래의 [그림 2]에 나와 있듯이 해시 테이블에 자료를 저장할 때는 Key 값을 해시함수에 대입하여 버킷 번호가 나오면 그 버킷의 빈 슬롯에 자료를 저장합니다.
Key 값을 해시 함수에 입력하여 나오는 버킷 번호에 자료를 넣으므로 많은 자료를 저장해도 삽입, 삭제, 검색 속도가 거의 일정합니다.
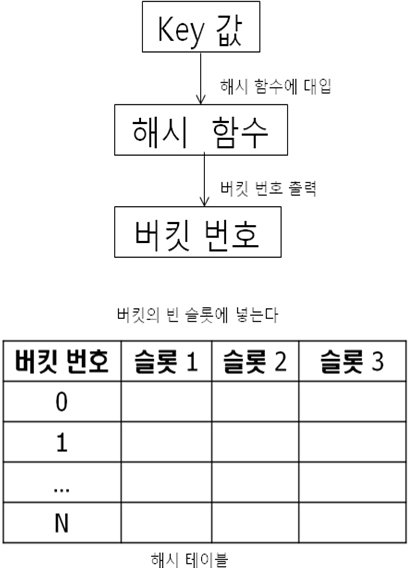
[그림 2] 해시 테이블에 자료 넣기
해시 테이블에 대한 설명은 간단하지 않고 이 글에서는 hash_map 사용법을 간단하게 설명하고 마치려 합니다. 좀 더 자세하게 알고 싶은 분들은 아래의 참고 항목을 꼭 봐 주세요.
[참고] 해시 테이블 설명
1. http://internet512.chonbuk.ac.kr/datastructure/hash/hash3.htm
2. 좋은 프로그램을 만드는 핵심 원리 25가지(한빛미디어)
6.4 hash_map을 사용할 때와 사용하지 않을 때
이전 연재에서 설명한 STL 컨테이너의 장단점은 컨테이너의 자료구조를 보면 알 수 있습니다. hash_map은 해시 테이블을 자료구조로 사용하므로 해시 테이블에 대해 알면 장단점을 파악할 수 있습니다. 해시 테이블은 많은 자료를 저장하고 있어도 검색이 빠릅니다. 그러나 저장한 자료가 적을 때는 메모리 낭비와 검색 시 오버헤드가 생깁니다.
Key 값을 해시 함수에 넣어 알맞은 버킷 번호를 알아 내는 것은 마법 같은 것이 아닙니다. 그러니 hash_map은 해시 테이블을 사용하므로 검색이 빠르다라는 것만 생각하고 무분별하게 hash_map을 사용하면 안됩니다. 컨테이너에 추가나 삭제를 하는 것은 list나 vector, deque가 hash_map보다 빠릅니다. 또 적은 요소를 저장하고 검색할 때는 vector나 list가 훨씬 빠를 수 있습니다. 수천의 자료를 저장하여 검색을 하는 경우에 hash_map을 사용하는 것이 좋습니다.
hash_map을 사용하는 경우
1. 많은 자료를 저장하고, 검색 속도가 빨라야 한다.
2. 너무 빈번하게 자료를 삽입, 삭제 하지 않는다.
6.5 Hash_map 사용방법
STL의 다른 컨테이너와 같이 사용하려면 먼저 헤더 파일과 namespace를 선언해야 합니다. 그러나 여기서 주의할 점은 앞서 이야기 했듯이 hash_map은 표준이 아니므로 표준 STL의 namespace와 다른 이름을 사용하므로 namespace 선언할 때 실수하지 않게 조심하세요.
hash_map 헤더파일을 포함합니다.
#include <hash_map>hash_map이 속한 namespace는 표준 STL과 다른 'stdext'입니다.
using namespace stdext;hash_map 선언은 아래와 같습니다.
hash_map< Key 자료 type, Value 자료 type > 변수 이름위에서는 Value는 저장할 데이터이고, Key는 Value와 가리키는 데이터입니다.
Key는 int, Value는 float를 사용한다면 아래와 같습니다.
hash_map< int, float > hash1;다른 컨테이너와 같이 동적 할당을 할 수 있습니다.
hash_map< key 자료 type, Value 자료 type >* 변수 이름 = new hash_map< key 자료 type, Value 자료 type >; hash_map< int, float >* hash1 = new hash_map< int, float >;hash_map은 Key와 Value가 짝을 이뤄야 하므로 hash_map을 처음 보는 분들은 이전의 시퀸스 컨테이너와 다르게 좀 복잡하게 보일 것입니다. 그러나 사용이 어려운 것은 아니니 잘 따라와 주세요.
6.5.1 hash_map의 주요 멤버들
| 멤버 | 설명 |
| begin | 첫 번째 원소의 랜덤 접근 반복자를 반환 |
| clear | 저장한 모든 원소를 삭제 |
| empty | 저장한 요소가 없으면 true 반환 |
| end | 마지막 원소 다음의(미 사용 영역) 반복자를 반환 |
| erase | 특정 위치의 원소나 지정 범위의 원소들을 삭제 |
| find | Key와 연관된 원소의 반복자 반환 |
| insert | 원소 추가 |
| lower_bound | 지정한 Key의 요소가 있다면 해당 위치의 반복자를 반환 |
| rbegin | 역방향으로 첫 번째 원소의 반복자를 반환 |
| rend | 역방향으로 마지막 원소 다음의 반복자를 반환 |
| size | 원소의 개수를 반환 |
| upper_bound | 지정한 Key 요소가 있다면 해당 위치 다음 위치의 반복자 반환 |
hash_map 컨테이너를 사용할 때는 거의 대부분 추가, 삭제, 검색 이렇게 3가지를 사용합니다. 핵심 기능인 만큼 아래에 좀 더 자세하게 설명하고, 다른 컨테이너는 앞서 설명한 것과 사용방법이 같으므로 예제 코드로 보여 드리겠습니다.
6.5.2 추가
insert
hash_map 에서는 자료를 추가 할 때 insert를 사용합니다.
원형 : pair <iterator, bool> insert( const value_type& _Val ); iterator insert( iterator _Where, const value_type& _Val ); template<class InputIterator> void insert( InputIterator _First, InputIterator _Last );insert를 사용하는 세 가지 방법 중 첫 번째 방식으로 Key 타입은 int, Value 타입은 float를 추가한다면
hash_map<int, float> hashmap1, hashmap2; // Key는 10, Value는 45.6f를 추가. hashmap1.insert(hash_map<int, float>::value_type(10, 45.6f));두 번째 방식으로는 특정 위치에 추가할 수 있습니다.
// 첫 번째 위치에 key 11, Value 50.2f를 추가 hashmap1.insert(hashmap1.begin(), hash_map<int, float>::value_type(11, 50.2f));세 번째 방식으로는 지정한 반복자 구간에 있는 것들을 추가합니다.
// hashmap1의 모든 요소를 hashmap2에 추가. hashmap2.insert( hashmap1.begin(), hashmap1.end() );6.5.3 삭제
erase
원형 : iterator erase( iterator _Where ); iterator erase( iterator _First, iterator _Last ); size_type erase( const key_type& _Key );첫 번째 방식은 특정 위치에 있는 요소를 삭제합니다.
// 첫 번째 위치의 요소 삭제. hashmap1.erase( hashmap1.begin() );두 번째 방식은 지정한 구역에 있는 요소들을 삭제합니다.
// hashmap1의 처음과 마지막에 있는 모든 요소 삭제 hashmap1.erase( hashmap1.begin(), hashmap1.end() );세 번째 방식은 지정한 키와 같은 요소를 삭제합니다.
// Key가 11인 요소 삭제. hashmap1.erase( 11 );첫 번째와 두 번째 방식의 반환 값으로는 삭제된 요소의 다음의 것을 가리키는 반복자이며 세 번째 방식은 삭제된 개수를 반환합니다.
6.5.4 검색
hahs_map에서 검색은 Key를 사용하여 같은 Key를 가지고 있는 요소를 찾습니다.
Key와 같은 요소를 찾으면 그 요소의 반복자를 반환하고, 찾지 못한 경우에는 end()를 가리키는 반복자를 반환합니다.
원형 : iterator find( const Key& _Key ); const_iterator find( const Key& _Key ) const;방식은 두 가지지만 사용법은 같습니다. 차이는 반환된 반복자가 const냐 아니냐의 차이입니다. 참고로 첫 번째 방식은 const가 아니므로 찾은 요소의 Value를 변경할 수 있습니다(참고로 Key는 변경 불가입니다). 두 번째 방식은 Value도 변경할 수 없습니다.
// Key가 10인 요소 찾기.
hash_map<int, float>::Iterator FindIter = hashmap1.find( 10 );
// 찾았다면 Value를 290.44로 변경
If( FindIter != hashmap1.end() )
{
FindIter->second = 290.44f;
}
begin, clear, count, empty, end, rbegin, rend, size는 앞서 말 했듯이 다른 컨테이너와 사용방법이 비슷하므로 아래 예제 코드를 통해서 사용법을 보여 드리겠습니다. [리스트 1] hash_map을 사용한 유저 관리
#include <iostream>
#include <hash_map>
using namespace std;
using namespace stdext;
// 게임 캐릭터
struct GameCharacter
{
// 아래의 인자를 가지는 생성자를 정의한 경우는
// 꼭 기본 생성자를 정의해야 컨테이너에서 사용할 수 있다.
GameCharacter() { }
GameCharacter( int CharCd, int Level, int Money )
{
_CharCd = CharCd;
_Level = Level;
_Money = Money;
}
int _CharCd; // 캐릭터 코드
int _Level; // 레벨
int _Money; // 돈
};
void main()
{
hash_map<int, GameCharacter> Characters;
GameCharacter Character1(12, 7, 1000 );
Characters.insert(hash_map<int, GameCharacter>::value_type(12, Character1));
GameCharacter Character2(15, 20, 111000 );
Characters.insert(hash_map<int, GameCharacter>::value_type(15, Character2));
GameCharacter Character3(200, 34, 3345000 );
Characters.insert(hash_map<int, GameCharacter>::value_type(200, Character3));
// iterator와 begin, end 사용
// 저장한 요소를 정방향으로 순회
hash_map<int, GameCharacter>::iterator Iter1;
for( Iter1 = Characters.begin(); Iter1 != Characters.end(); ++Iter1 )
{
cout << "캐릭터 코드 : " << Iter1->second._CharCd << " | 레벨 : " << Iter1->second._Level
<< "| 가진 돈 : " << Iter1->second._Money << endl;
}
cout << endl;
// rbegin, rend 사용
// 저장한 요소의 역방향으로순회
hash_map<int, GameCharacter>::reverse_iterator RIter;
for( RIter = Characters.rbegin(); RIter != Characters.rend(); ++RIter )
{
cout << "캐릭터 코드 : " << RIter->second._CharCd << " | 레벨 : " << RIter->second._Level
<< "| 가진 돈 : " << RIter->second._Money << endl;
}
cout << endl << endl;
// Characters에 저장한 요소 수
int CharacterCount = Characters.size();
// 검색.
// 캐릭터 코드 15인 캐릭터를 찾는다.
hash_map<int, GameCharacter>::iterator FindIter = Characters.find(15);
// 찾지 못했다면 FindIter은 end 위치의 반복자가 반환된다.
if( Characters.end() == FindIter )
{
cout << "캐릭터 코드가 20인 캐릭터가 없습니다" << endl;
}
else
{
cout << "캐릭터 코드가 15인 캐릭터를 찾았습니다." << endl;
cout << "캐릭터 코드 : " << FindIter->second._CharCd << " | 레벨 : " << FindIter->second._Level
<< "| 가진 돈 : " << FindIter->second._Money << endl;
}
cout << endl;
for( Iter1 = Characters.begin(); Iter1 != Characters.end(); ++Iter1 )
{
cout << "캐릭터 코드 : " << Iter1->second._CharCd << " | 레벨 : " << Iter1->second._Level
<< "| 가진 돈 : " << Iter1->second._Money << endl;
}
cout << endl << endl;
// 삭제
// 캐릭터 코드가 15인 캐릭터를 삭제한다.
Characters.erase( 15 );
for( Iter1 = Characters.begin(); Iter1 != Characters.end(); ++Iter1 )
{
cout << "캐릭터 코드 : " << Iter1->second._CharCd << " | 레벨 : " << Iter1->second._Level
<< "| 가진 돈 : " << Iter1->second._Money << endl;
}
cout << endl << endl;
// 모든 캐릭터를 삭제한다.
Characters.erase( Characters.begin(), Characters.end() );
// Characters 공백 조사
if( Characters.empty() )
{
cout << "Characters는 비어 있습니다." << endl;
}
}
결과 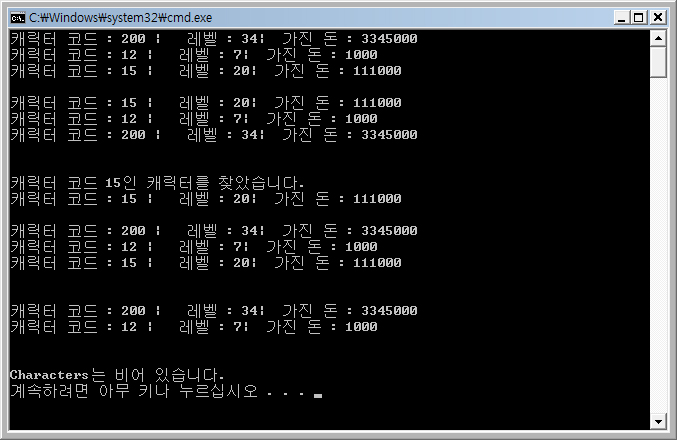
6.5.5 lower_bound와 upper_bound
hash_map에 저장한 요소 중에서 Key 값으로 해당 요소의 시작 위치를 얻을 때 사용하는 멤버들입니다. Key 값의 비교는 크기가 아닌 저장 되어 있는 요소의 순서입니다. 23, 4, 5, 18, 14, 30 이라는 순서로 Key 값을 가진 요소가 저장되어 있으며 Key 값 18과 같거나 큰 것을 찾으면 18, 14, 30이 됩니다.
lower_bound
Key가 있다면 해당 위치의 반복자를 반환합니다.
원형 : iterator lower_bound( const Key& _Key ); const_iterator lower_bound( const Key& _Key ) const;upper_bound
Key가 있다면 그 요소 다음 위치의 반복자를 반환합니다.
원형 : iterator lower_bound( const Key& _Key ); const_iterator lower_bound( const Key& _Key ) const;lower_bound와 upper_bound는 hahs_map에 저장된 요소를 일부분씩 나누어 처리를 할 때 유용합니다. 예를 들면 hash_map에 3,000개의 게임 캐릭터 정보를 저장되어 있으며 이것을 100개씩 나누어서 처리하고 싶을 때 사용하면 좋습니다.
[리스트 2] lower_bound와 upper_bound 사용 예
#include <iostream>
#include <hash_map>
using namespace std;
using namespace stdext;
// 게임 캐릭터
struct GameCharacter
{
GameCharacter() { }
GameCharacter( int CharCd, int Level, int Money )
{
_CharCd = CharCd;
_Level = Level;
_Money = Money;
}
int _CharCd; // 캐릭터코드
int _Level; // 레벨
int _Money; // 돈
};
void main()
{
hash_map<int, GameCharacter> Characters;
GameCharacter Character1(12, 7, 1000 );
Characters.insert(hash_map<int, GameCharacter>::value_type(12, Character1));
GameCharacter Character2(15, 20, 111000 );
Characters.insert(hash_map<int, GameCharacter>::value_type(15, Character2));
GameCharacter Character3(7, 34, 3345000 );
Characters.insert(hash_map<int, GameCharacter>::value_type(7, Character3));
GameCharacter Character4(14, 12, 112200 );
Characters.insert(hash_map<int, GameCharacter>::value_type(14, Character4));
GameCharacter Character5(25, 3, 5000 );
Characters.insert(hash_map<int, GameCharacter>::value_type(25, Character5));
hash_map<int, GameCharacter>::iterator Iter1;
cout << "저장한 캐릭터 리스트" << endl;
for( Iter1 = Characters.begin(); Iter1 != Characters.end(); ++Iter1 )
{
cout << "캐릭터 코드 : " << Iter1->second._CharCd << " | 레벨 : " << Iter1->second._Level
<< "| 가진 돈 : " << Iter1->second._Money << endl;
}
cout << endl;
cout << "lower_bound(14)" <<endl;
hash_map<int, GameCharacter>::iterator Iter = Characters.lower_bound(14);
while( Iter != Characters.end() )
{
cout << "캐릭터 코드 : " << Iter->second._CharCd << " | 레벨 : " << Iter->second._Level
<< "| 가진 돈 : " << Iter->second._Money << endl;
++Iter;
}
cout << endl;
cout << "upper_bound(7)" <<endl;
Iter = Characters.upper_bound(7);
while( Iter != Characters.end() )
{
cout << "캐릭터 코드 : " << Iter->second._CharCd << " | 레벨 : " << Iter->second._Level
<< "| 가진 돈 : " << Iter->second._Money << endl;
++Iter;
}
}
결과
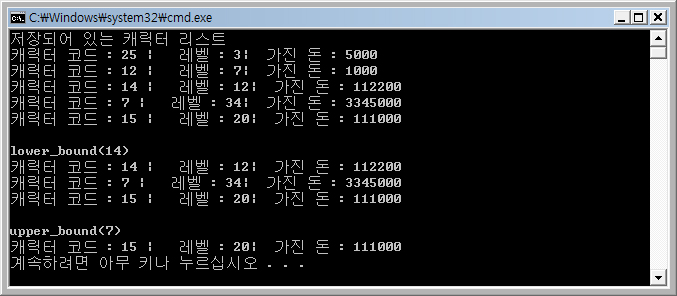
이것으로 hash_map의 주요 사용법에 대한 설명이 끝났습니다.
위에 설명한 것들만 알고 있으면 hash_map을 사용하는데 문제가 없을 것입니다.
위에 설명한 것들 이외의 hash_map의 멤버들에 대해서 알고 싶으며 마이크로소프트의 MSDN 사이트에 있는 것을 참고하세요
http://msdn.microsoft.com/en-us/library/h80zf4bx(VS.80).aspx
[참고]
Visual C++의 hash_map의 성능에 대해서 Visual C++에 있는 hash_map은 다른 컴파일에서 구현한 것보다 꽤 느리다라는 말이 있습니다.
(관련 글은 여기서 참고하세요. http://minjang.egloos.com/1983788 http://junyoung.tistory.com/1)
얼마나 느린지 테스트했습니다.
http://blog.naver.com/jacking75/140062720030
제가 조사한 것은 Windows 플랫폼에서 VC++에서 제공한 라이브러리로 테스트한 것입니다.
결과를 보면 hash_map이 map보다 빠르지도 않고 특히 hash_map과 같은 자료구조를 사용하는 컨테이너로 마이크로소프트사에서 만든 CAtlMap에 비해 속도가 아주 느립니다.
성능이 중요한 곳에 hash_map을 사용한다면 VC++에 있는 것을 사용하지 말고 자체적으로 잘 만들어진 hash 함수를 사용하거나 C++ 오픈 소스 라이브러리인 boost에 있는 unordered_map을 사용하는 것이 좋을 것 같습니다. Windows 플랫폼에서만 사용한다면 CAtlMap을 사용하는 것도 좋습니다.
출처 : http://network.hanb.co.kr/view.php?bi_id=1617
'프로그래밍 > 공부관련' 카테고리의 다른 글
| shared_ptr (0) | 2010.01.07 |
|---|---|
| 이제 데이터 멤버는 private , protected를 적용하자. (0) | 2010.01.06 |
| 스레드 클래스 함수 (1) | 2009.12.31 |
| 11월 23일 플로렌스2 - 개발 1 (0) | 2009.11.23 |
| 11월22일 플로렌스2 - 기획 1 (0) | 2009.11.23 |
